Models Servings
Introduction
The Model Servings page enables DIAL admins to deploy and manage containers for AI models listed at NVIDIA NIM and Hugging Face.
How to Use Models
To be able to use AI models in DIAL, you need adapters. Model adapters unify the APIs of respective AI models to align with the Unified Protocol of DIAL Core. DIAL includes adapters for Azure OpenAI models, GCP Vertex AI models, and AWS Bedrock models. You can also create custom adapters for other AI models with DIAL SDK.
You can use DIAL OpenAI adapter to work with compatible models listed on Hugging Face or NVIDIA NIM. For other models not compatible with OpenAI API, you need to create custom adapters.
To enable a model in DIAL:
- Add and run a model serving container with an OpenAI-compatible model from Hugging Face or NIM.
- Unless it is a part of your DIAL setup, create a new adapter based on DIAL Azure OpenAI Adapter and add it in Builders/Adapters.
- In Entities/Models, create a new model entity:
- As a Source Type, select your OpenAI adapter.
- As an Override Name, use the model name from the running model serving container. You can find it in the container logs.
- Add Upstream Endpoint with the URL of your model serving running container. Follow this pattern:
http://<container_url>/openai/v1/chat/completions.
- Now the AI model is available for users and apps based on your permissions model.
Main Screen
On the main screen, you can view existing and add new AI model servings.
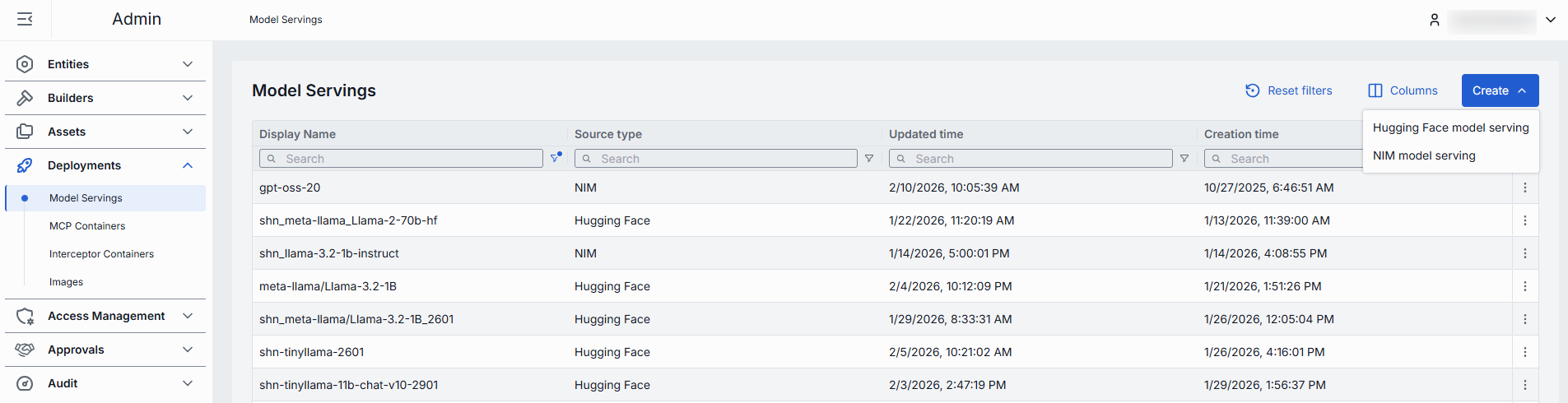
Model servings grid
| Field | Description |
|---|---|
| Display Name | Name of the model serving rendered on UI. |
| Description | Brief description of the model serving. |
| Source Type | Source type of the model (NIM or Hugging Face). |
| Status | Current status of the model serving. |
| ID | Unique identifier for the model serving. |
| Container URL | URL of the container where the model is hosted. Available for a running container. |
| Author | Email address of the creator of the model serving. |
| Topics | List of topics associated with the model serving. |
| Creation Time | Creation timestamp. |
| Updated Time | Timestamp of the last update. |
Create Model Serving
On the main screen, use the Create button to create Hugging Face or NIM model servings.
Note: Available deployment options depend on the current setup.
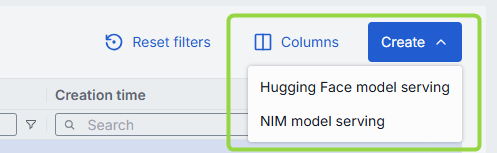
To create a new model serving:
- Click the Create button on the main screen and select which type of model serving you want to create.
- Fill in the required fields in the Model Serving form:
- ID: Unique identifier for the model serving.
- Display Name: Enter a name for the model serving displayed on UI.
- Description: Provide a brief description of the model serving.
- Hugging Face Model Name: Applies to Hugging Face source type. Start typing the name of the model to see suggestions or click Select from registry to pick in the pop-up modal window.
- Docker Image URI: Applies to NIM source type. Enter the Docker image URI for the model.
- Click the Create button to submit the form and create the model serving.
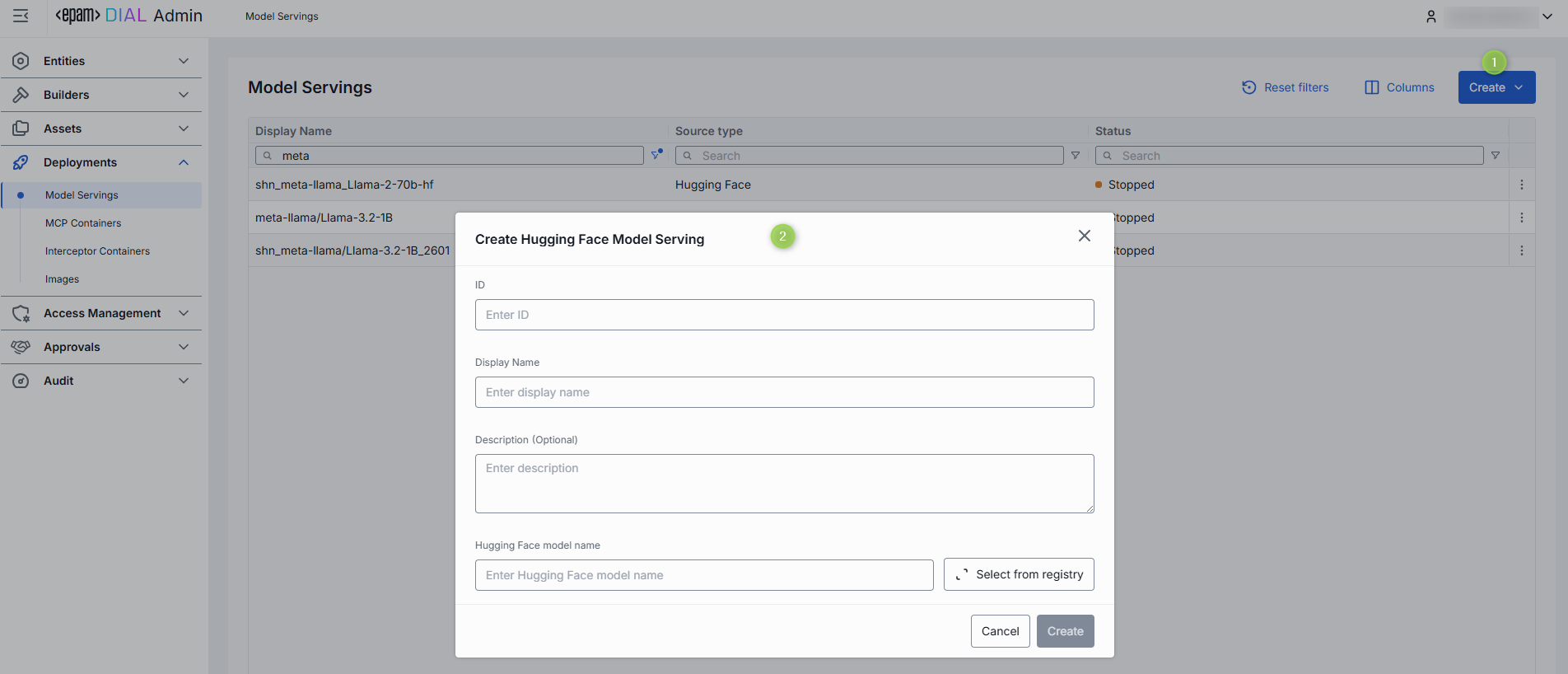
Configuration
Click any model serving from the main screen to open its configuration.
Note: Configuration fields are disabled for editing when the container is in a transition state (launching or stopping).
Actions
In the header of the Configuration screen, you can find the following action buttons:
| Action | Description |
|---|---|
| Create Model | Available for running model servings. Click to create a new model deployment using this selected model serving. |
| Run/Stop | Click to start or stop the selected model serving. |
| Delete | Click to delete the selected model serving container. Note: This will effect model deployments created based on the deleted container. |

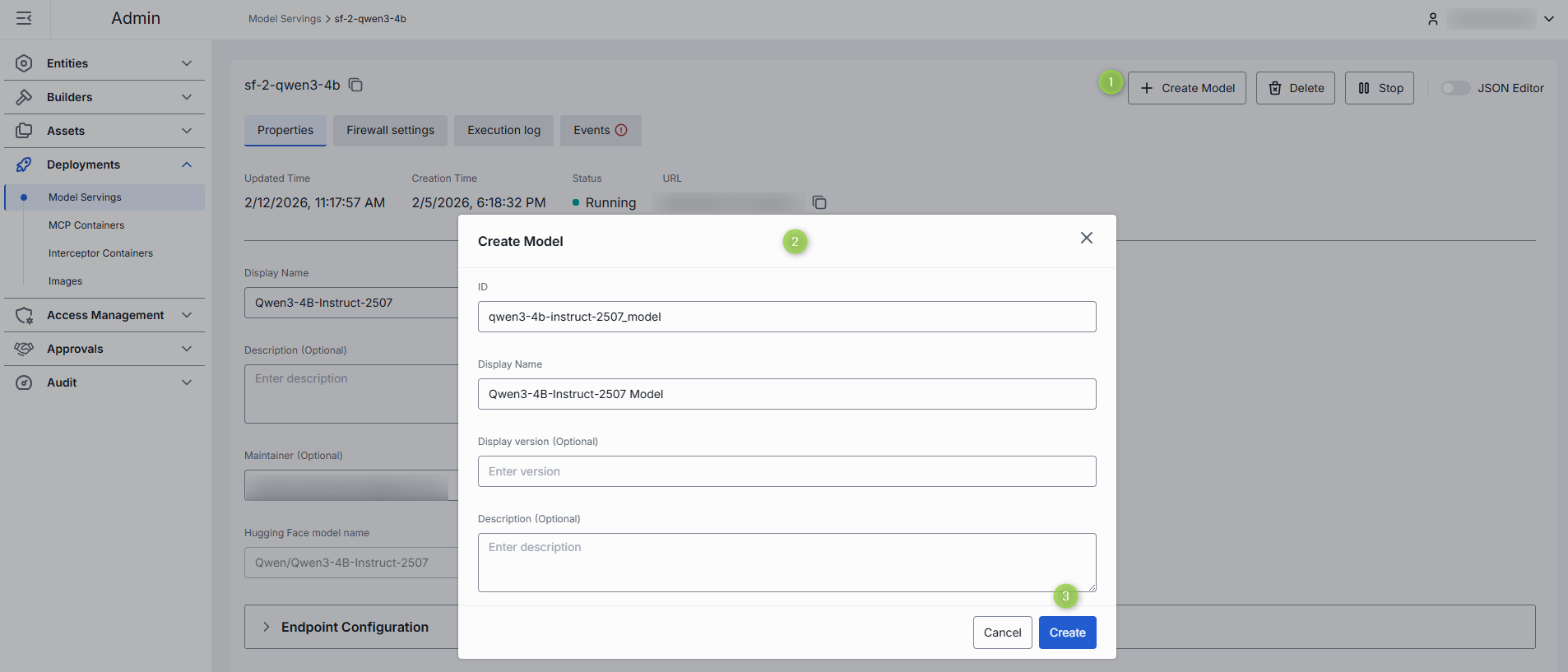
To Create Model
You can use a running model serving container to create a new model deployment in DIAL. Once created, the model deployment appears in Entities/Models. Refer to How to Use Models section for more details on how to enable models in DIAL.
- In the Configuration screen of the running model serving, click the Create Model button in the header.
- In the Create Model dialog, fill in the form fields:
- ID: Unique identifier for the model deployment. Auto-populated according to the selected model serving.
- Display Name: Enter a name for the model deployment. Auto-populated according to the selected model serving.
- Display Version: Specify a version of the model deployment.
- Description: Provide a brief description of the model deployment.
- Click the Create button to submit the form and create the model deployment. Repeat these steps to create more model deployments if needed.
Properties
In the Properties tab, you can view and edit the selected model serving container settings.
| Property | Required | Editable | Description |
|---|---|---|---|
| ID | - | No | Unique read-only identifier of the model serving container. Must be between 2 and 36 characters long. Can contain only lowercase Latin letters, numbers, and hyphens. |
| Creation Time | - | No | Creation timestamp. |
| Updated Time | - | No | Timestamp of the last update. |
| Status | - | No | Current status of the model serving container. |
| Restarts | - | No | Restart counter for launching containers. You can find details in the Execution Log. |
| URL | - | No | URL of the running container where the model is hosted. |
| Display Name | Yes | Yes | Name of the model serving container rendered in UI. Must be between 2 and 255 characters long. |
| Description | No | Yes | Brief description of the model serving container. |
| Maintainer | No | Yes | Person or team responsible for maintaining the model serving container. |
| Topics | No | Yes | List of topics associated with the model serving. Click to display a list of available topics. You can add your own custom topics to the list following these rules: - The topic name must not exceed 255 characters. - The topic name must not contain leading or trailing spaces. |
| Hugging Face model name | Conditional | Yes | Applies to Hugging Face models. The name of the model from Hugging Face. Start typing the name of the model to see suggestions or click Select from registry to pick in the pop-up modal window. |
| Docker Image URI | Conditional | Yes | Applies to NIM models. The Docker image URI for the model. |
| Endpoint Configuration | No | Yes | Port configuration for the model serving. Note: Changes to these settings can be applied to a running container. Saving changes will trigger a restart in RollingUpdate mode. |
| Autoscaling | No | Yes | Parameters to dynamically adjust model serving replicas based on demand. Note: Autoscaling controls are available for Hugging Face model servings. - Automatic scale to zero: Use to define criteria to reduce replicas to zero to save resources. Model servings are created with always-on defaults, so scale-to-zero is not enabled by default. - Min and Max Replicas: Sets the minimum and maximum number of model instances that can run, ensuring availability and controlling costs. For new NIM and Hugging Face model servings, both values default to 1 replica. - Pending requests to trigger autoscaling: Specifies the number of queued requests required to trigger scaling up, helping maintain performance during traffic spikes. Important: Existing model serving containers keep their current autoscaling configuration. |
| Environment Variables | No | Yes | List of environment variables for the model serving. Note: Changes to these settings can be applied to a running container. Saving changes will trigger a restart in RollingUpdate mode. - Name: Must be between 1 and 253 characters long. Can contain only letters, numbers, dots (.), hyphens (-), and underscores (_).- Value: Must be between 1 and 253 characters long. Can contain only letters, numbers, dots (.), hyphens (-), and underscores (_). |
| Resources | No | Yes | Resource allocation settings for the model serving (CPU, Memory, GPU). Note: Changes to these settings can be applied to a running container. Saving changes will trigger a restart in RollingUpdate mode. Validation rules: - Values must be numeric and greater than 0. - Maximum allowed values for cpu, memory, and nvidia.com/gpu are defined on the backend via environment variables.- For each matching resource key (e.g. cpu), the value in limits must not be less than the value in requests. |
| Configuration | No | Yes | Command that defines the executable and its options to launch the model serving. Arguments provide extra parameters for customization during startup. |
| Startup probe | No | Yes | Use this configuration to enable and configure the Startup Probe - it is a type of health check specifically designed to signal that the application inside the container is ready to begin serving traffic. - Type: HTTP (Performs an HTTP GET request to a specified path and port on the container. The probe is considered successful if the response has a status code between 200 and 399.); TCP (Attempts to establish a TCP connection to the specified port. The probe is successful if the connection is established.). - Port: The network port on the container to which the probe will connect or send the request. - Path: Path to call inside the container. Available for HTTP type. - Initial delay seconds: The number of seconds to wait after the container starts before performing the first probe. This allows the application time to initialize before health checks begin. - Period seconds: The interval (in seconds) between consecutive probe checks. This determines how frequently Kubernetes will perform the probe. - Timeout seconds: The maximum number of seconds allowed for a single probe check to complete. If the probe does not return within this time, it is considered a failure. - Failure threshold: The number of consecutive failed probe attempts before Kubernetes considers the startup probe to have failed, which may result in the container being restarted or marked as failed. |
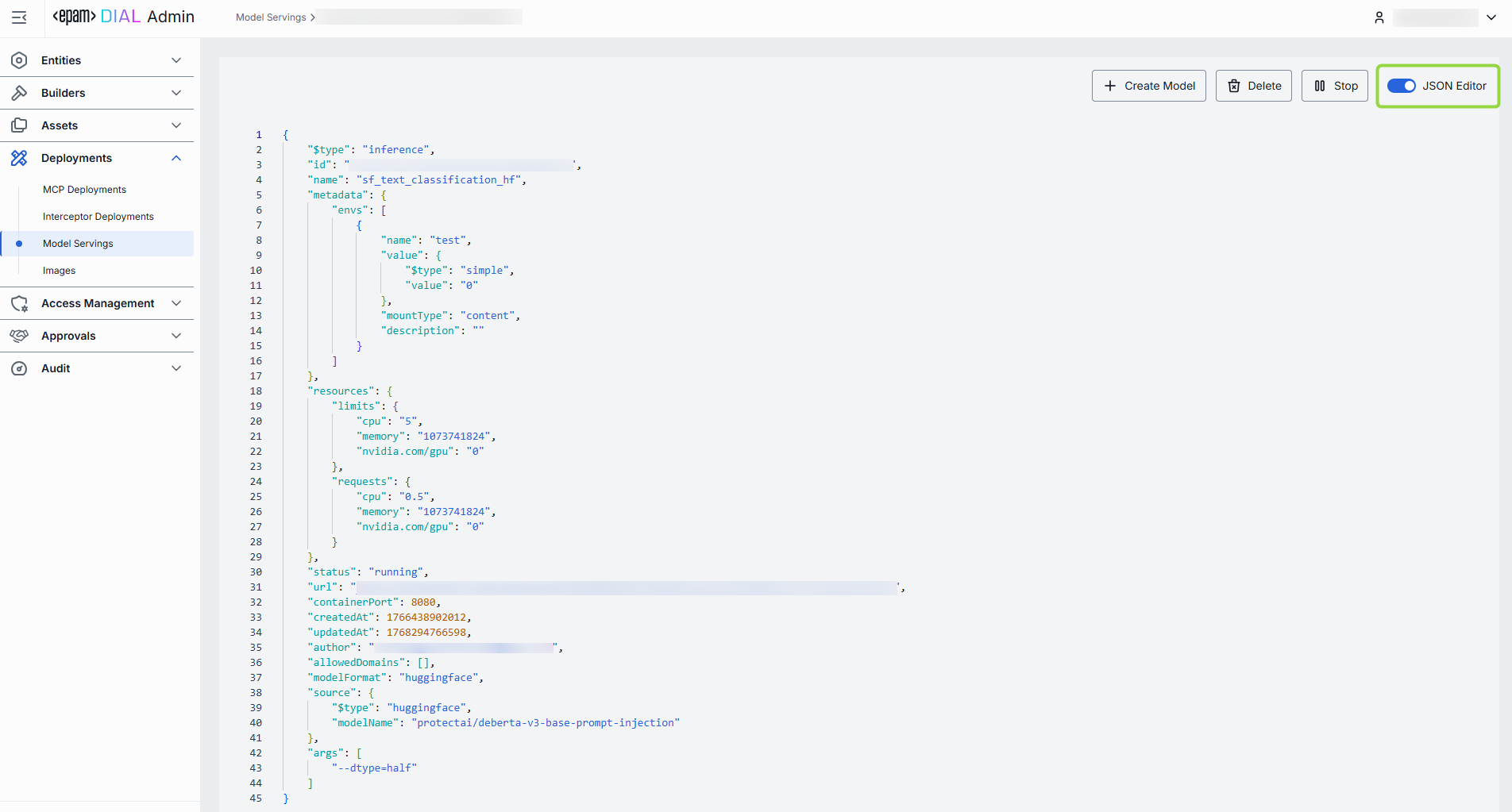
Advanced users with technical expertise can work with model serving properties in the table or a JSON editor view modes. It is useful for advanced scenarios of bulk updates, copy/paste between environments, or tweaking settings not exposed on UI.
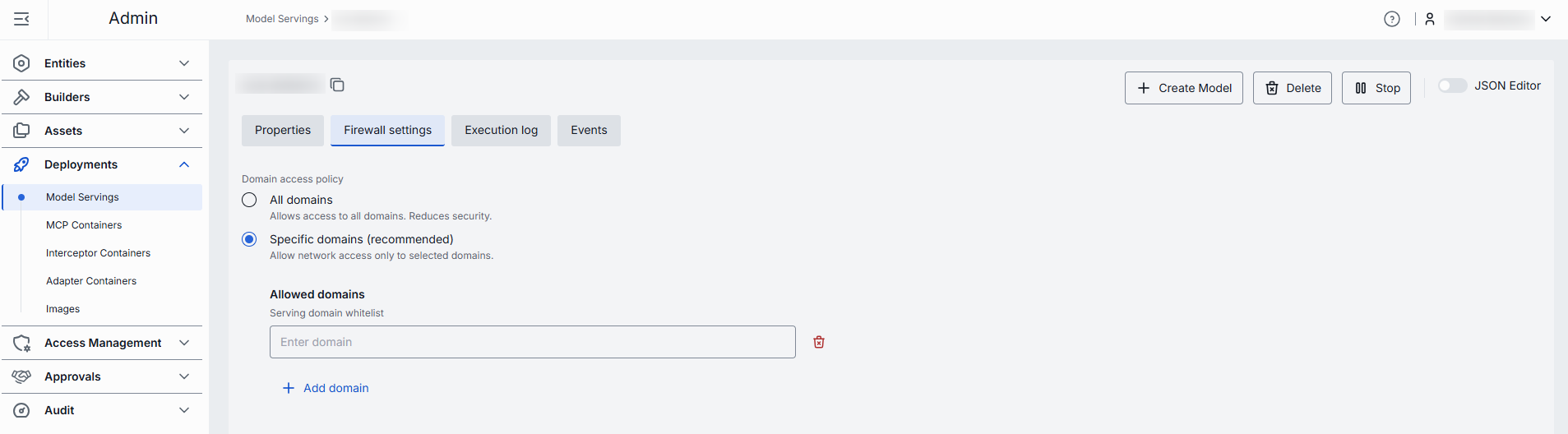
Firewall settings
The whitelist domains setting specifies which external domains the model serving container is allowed to connect to. This setting controls outgoing traffic from the container, ensuring that it can only communicate with trusted domains (for example, your company’s website or specific client applications).
Domain name requirements: Enter the domain name without protocol, e.g., github.com. Each domain must have at least one dot, labels can include letters, numbers, and hyphens (1–63 chars, not starting or ending with a hyphen), and the top-level domain must be at least 2 letters. Domain name must not include leading or trailing hyphens in labels.
Execution log
In the Execution Log tab, you can view the logs related to the operations and activities of the selected model serving container.
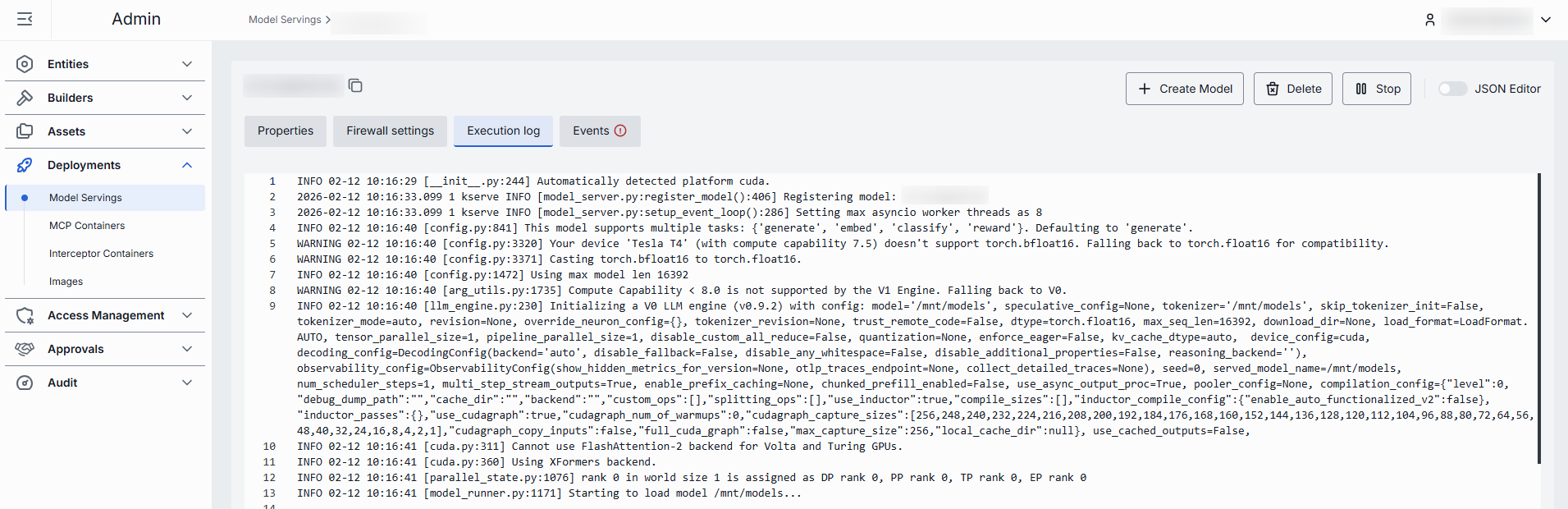
When container starts with more than one pod, you can see logs for each of them:

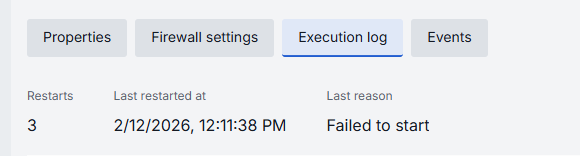
In case of issues, health indicators are displayed to help identify problems:
| Indicator | Description |
|---|---|
| Restarts | Restart counter for launching containers. Use to identify crash loops. |
| Last restarted at | Timestamp of the last model serving restart. |
| Last reason | Restart failure reason. |
Events
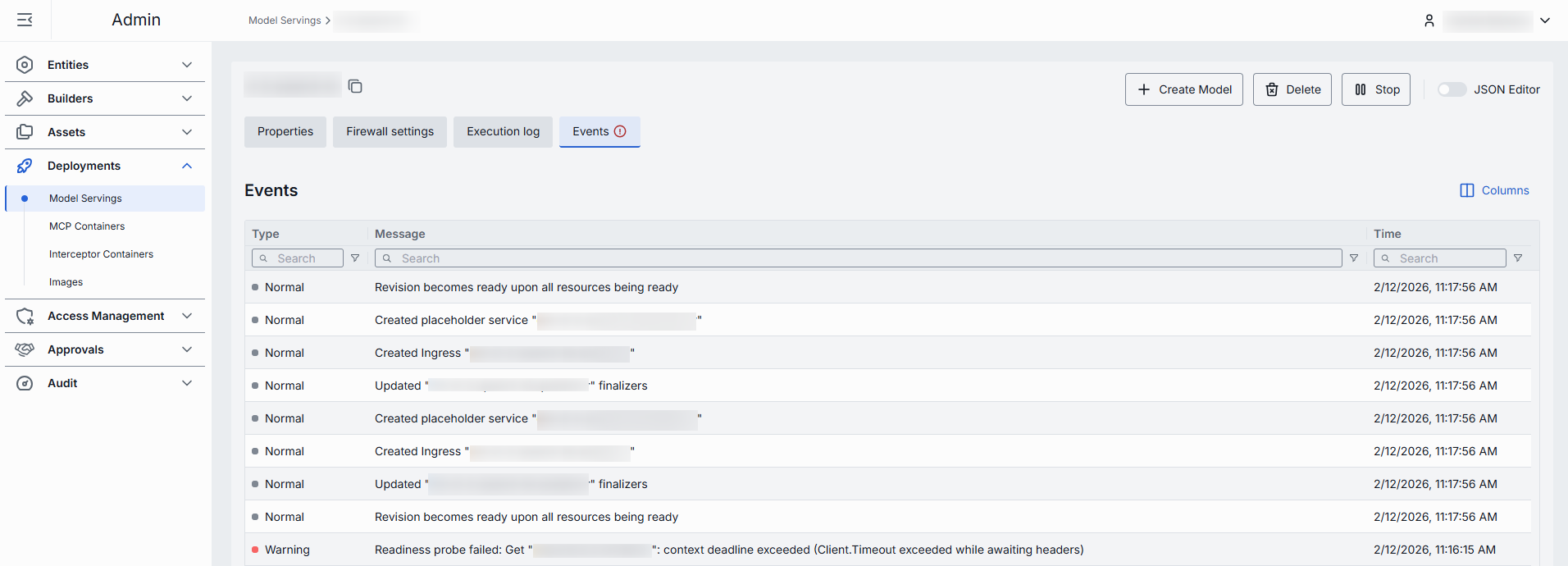
In the Events tab, you can view the event history related to the selected model serving.
Audit
In the Audit tab, you can review activity, usage, and operational metrics for the selected model serving container, including configuration changes and runtime actions.
Note: This tab mimics the functionality available in the global Activity section, but is scoped specifically to the selected model serving.